Spark submit python wordcount on yarn cluster mode
最近这段时间补习了下 Spark 相关的知识点,也纠正了之前不少错误的理解,总的来说实践出真理,只有动手才能更好的理解。这篇文章主要记录第一次使用 spark 结合 hadoop 跑 python 程序的过程,算是大数据学习的起点吧。
Spark 的运行模式
官网上已经很详细的介绍了几种模式,我就总结下:
1. Local
由于本地资源有限,用于开发测试用,验证代码。
2. Standalone
Spark 自身组成的集群,和 hdfs 一样有 master,slave 的概念,自己做资源的调度,一般不用于生产环境。
3. Mesos
运行在 Apache mesos 上,由 mesos 做资源调度,由于 Mesos 市场占有率不断下滑,不是一个好选择。
4. YARN
由 Hadoop Yarn 做资源调度,Spark + Hadoop 黄金组合。
5. K8s
运行在 kubernetes 之上,application 跑在 docker 上,dockerized!整个公司服务容器化,计划下一阶段尝试使用。
Spark 的 Deploy-mode
关于两种 deploy-mode,区别就在与 Driver Program 运行的位置,参见下图:
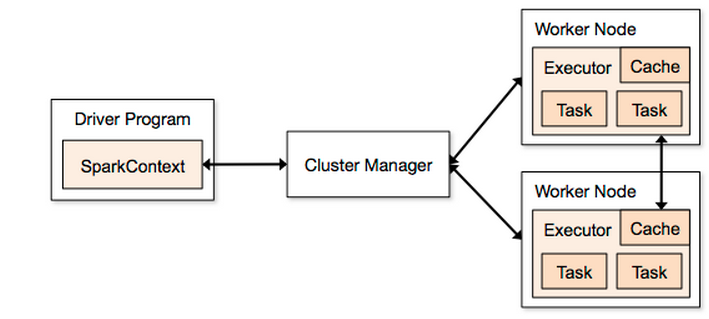
1. client mode
Driver Program 跑在本地,spark-shell 就是这种模式,能够及时得到 job 的返回结果,使用场景比如说写一个 RESTful 的 webserver,通过 API 提交 job 给 spark,及时返回运算结果。
2. cluster mode
Driver Program 跑在负责资源管理的节点,使用场景一般为耗时长的任务,因为输出结果 client 无法直接拿到,只能输出到其他地方,如 hdfs。
安装部署
本文使用场景为 Spark on YARN,所以部署方式很简单。
1
2
3
4
5
6
7
8
9
10
1. 下载解压
# cd /usr/local/
# wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
# tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz
# ln -s spark spark-*
2. 配置`HADOOP_CONF_DIR`路径
# scp your_hadoop_conf_dir /usr/local/hadoop/etc/
# export HADOOP_CONF_DIR="/usr/local/spark/hadoop"
3. 安装jdk
# yum install java
Run!
作为一名 pythoner,先跑一个 wordcount 吧。
需求是在 hdfs 上存在一个 test.txt 文件,统计其每个单词的数量,结果导出到 hdfs 的 output.txt 文件中。
wordcount.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import sys
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
# create Spark context with Spark configuration
conf = SparkConf().setAppName("Word Count - Python")
sc = SparkContext(conf=conf)
# read in text file and split each document into words
words = sc.textFile("hdfs:///input/test.txt").flatMap(lambda line: line.split(" "))
# count the occurrence of each word
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a,b:a +b)
wordCounts.saveAsTextFile("hdfs:///output.txt")
test.txt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[hadoop@hp2 hadoop]$ cat test.txt
test word
test word
test word
test word
test word
test word
test word
test word
test word
apple
apple
apple
apple
apple
apple
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# upload to hdfs
[hadoop@hp2 hadoop]$ hdfs dfs -put test2.txt /input/test.txt
# run spark-submit
[hadoop@hp2 hadoop]$ ./bin/spark-submit --master yarn --deploy-mode cluster --executor-memory 1G --driver-memory 1G wordcount.py
...
2018-07-06 15:48:38 INFO Client:54 - Application report for application_1530690347064_0020 (state: RUNNING)
2018-07-06 15:48:39 INFO Client:54 - Application report for application_1530690347064_0020 (state: RUNNING)
2018-07-06 15:48:40 INFO Client:54 - Application report for application_1530690347064_0020 (state: FINISHED)
2018-07-06 15:48:40 INFO Client:54 -
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.1.222
ApplicationMaster RPC port: 0
queue: default
start time: 1530863301707
final status: SUCCEEDED
tracking URL: http://hp3:8088/proxy/application_1530690347064_0020/
user: hadoop
2018-07-06 15:48:40 INFO ShutdownHookManager:54 - Shutdown hook called
2018-07-06 15:48:40 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-efa8ca8d-83fa-4641-9aa4-3bebcc7d365a
2018-07-06 15:48:40 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-7c6f554c-3d84-4567-bb55-dd32be2e4be9
# get wordcount result
[hadoop@hp2 hadoop]$ hdfs dfs -ls /
Found 2 items
drwxrwxr-x - hadoop hadoop 0 2018-06-15 17:35 /input
drwxrwxr-x - hadoop hadoop 0 2018-07-06 15:48 /output.txt
[hadoop@hp2 hadoop]$ hdfs dfs -get /output.txt
[hadoop@hp2 hadoop]$ ls -l output.txt/
total 8
-rw-rw-r-- 1 hadoop hadoop 26 Jul 6 17:17 part-00000
-rw-rw-r-- 1 hadoop hadoop 14 Jul 6 17:17 part-00001
-rw-rw-r-- 1 hadoop hadoop 0 Jul 6 17:17 _SUCCESS
[hadoop@hp2 hadoop]$ cat output.txt/*
(u'test', 9)
(u'word', 9)
(u'apple', 6)
saveAsTextFile 保存结果是目录,这里做测试以为是文件,所以命名为 output.txt。